Un case study ufficiale targato Adamantia Group in cui raccontiamo una customer story in diretta, affrontando le sfide della modernità a colpi di Intelligenza Artificiale
Background
Meet Giorni Ferro
La Giorni Ferro Spa nasce nel 1950 dall’iniziativa di Ferdinando Giorni con l’obiettivo di fornire al Paese materiali e attrezzature per la ricostruzione postbellica.
La continua crescita della Giorni Ferro S.p.A. ha reso necessario negli anni l’ampliamento costante dei propri uffici, magazzini e laboratori, che oggi occupano una superficie di 25.000 mq., di cui 10.000 coperti, ove i clienti possono ricevere tutto il supporto professionale di cui necessitano.
LA SFIDA
Esigenze & Obiettivi
Giorni Ferro riceve ogni anno circa 1000 documenti (DDT e certificati di origine/qualità) da parte dei fornitori. Questi documenti vengono inviati via email in formato PDF o in formato cartaceo. Gli operatori sono responsabili dell’archiviazione e dell’inserimento di questi documenti nel WMS (Warehouse Management System).
Il processo attuale di archiviazione e classificazione dei documenti è manuale e richiede tempo. Al momento i documenti vengono organizzati in cartelle e rinominati manualmente.
Un volta effettuata l’archiviazione, gli operatori devono anche allegare i certificati di origine/qualità ai DDT. Questo processo è essenziale per garantire che i certificati siano disponibili per le spedizioni e che i clienti possano ricevere la documentazione necessaria.
Per effettuare questa operazione, gli operatori devono separare manualmente i certificati in immagini e allegarli alle righe corrispondenti dei DDT nel WMS.
L’obiettivo di questo progetto è ridurre drasticamente il tempo necessario all’archiviazione e alla classificazione dei documenti rendendo il processo quasi totalmente automatico.
LA SOLUZIONE
IA Generativa
In base a queste considerazioni, si é deciso di implementare un sistema che prevede:
archiviazione dei documenti in un database
ricerca dei documenti tramite attributi definiti dall’utente (fornitore, numero, data, ecc.)
suddivisione automatica dei documenti in immagini
definizione di template per l’estrazione automatica dei dati
utilizzo di AI generativa per i documenti non riconosciuti
Pipeline di elaborazione dei documenti
La pipeline di elaborazione dei documenti prevede i seguenti passaggi:
Suddivisione dei documenti in immagini
Correzione dell’orientamento e della distorsione (Hough Lines)
Estrazione del testo completo tramite OCR
Applicazione dell’estrazione basata su template (se viene trovata una corrispondenza)
Fallback all’AI generativa per l’estrazione
come funzionano
I Template
Gli utenti possono selezionare le aree chiave di interesse nel documento. L’estrazione dei campi rilevanti avviene tramite regex-based matching. I dati estratti vengono assegnati ai campi del database.
In fase di creazione del template, l’utente può anche definire un numero di documenti simili per validare la correttezza dell’estrazione. In questo modo, ci si assicura che il template sia stato implementato correttamente e che i dati estratti siano accurati.
come entra in gioco
IA Generativa
Nel caso in cui non venga trovata una corrispondenza con i template definiti, si può ricorrere a un modello di IA generativa per l’estrazione dei dati.
In questo caso, le soluzioni possibili sono molteplici. Si può decidere di utilizzare un servizio esterno (ad esempio OpenAI) oppure un modello locale. In entrambe i casi, si può ricorrere a modelli generalizzati (come GPT-4o) o modelli addestrati tramite fine-tuning su dati specifici del dominio (come T5 o GPT-4o-mini).
Tutte le soluzione sono state testate e implementate nel progetto.
CARATTERISTICHE
Tecniche e Tecnologiche
Si è scelto un architettura client/server con interfaccia web per l’interazione con gli utenti. Il server è responsabile dell’elaborazione dei documenti e della gestione del database, mentre il client fornisce un’interfaccia utente intuitiva per la ricerca e la visualizzazione dei documenti.
Il vantaggio di questa architettura è la separazione tra frontend e backend, che consente una maggiore flessibilità e scalabilità. Inoltre il backend è dotato di un interfaccia RESTful per l’interazione con il client, che quindi consente l’integrazione con altri sistemi e applicazioni.
Il linguaggio di programmazione scelto per il backend è Python, che offre una vasta gamma di librerie e framework per l’elaborazione dei documenti e l’implementazione di modelli di IA. Per il frontend è stato scelto
Angular, il framework di Google per la creazione di applicazioni web moderne e reattive.
Il database scelto è SQLite, un database relazionale leggero e facile da usare. L’applicazione non necessita di un server database dedicato data la quantità limitata di dati da gestire, in quanto file (PDF e immagini) vengono ovviamente archiviati nel filesystem, lasciando al database solo i metadati relativi ai documenti.
Tutta la parte di riconoscimento ottico dei caratteri (OCR) e di estrazione dei dati è gestita tramite Tesseract, il motore OCR open source sviluppato da Google.
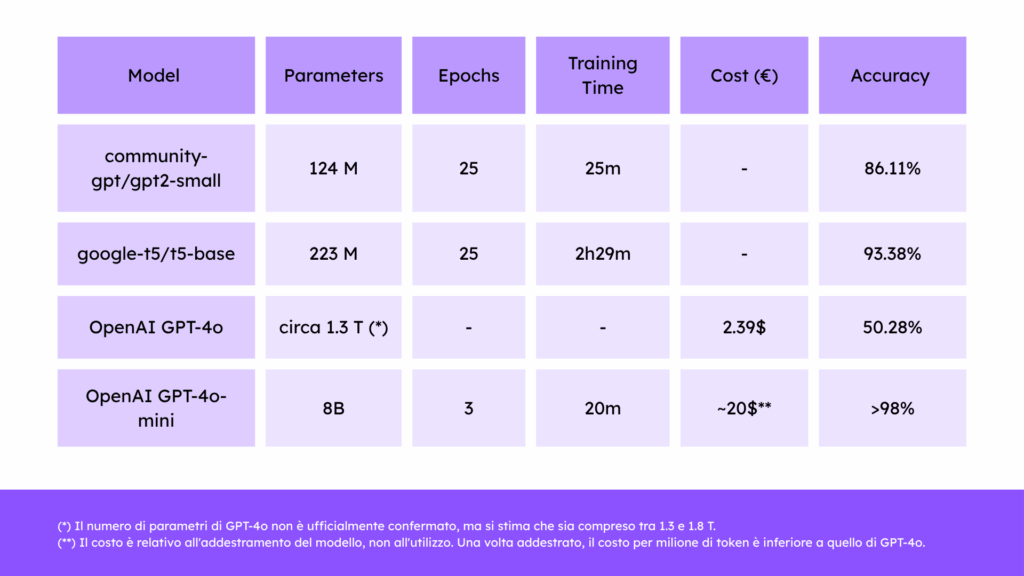
Per quanto invece riguarda l’estrazione dei dati tramite AI generativa, sono stati testati diversi modelli, tra cui GPT-2, T5, GPT-4o e GPT-4o-mini. I risultati ottenuti sono stati confrontati e analizzati per valutare le performance e l’accuratezza dei modelli.
Performance & Risultati
I seguenti risultati sono relativi ai documenti dell’anno 2023 (circa 800 documenti).
Tramite la definizione di circa 40 template è stato possibile ottenere classificare il 70% dei documenti in modo automatico e preciso.
Successivamente i dati ottenuti sono stati utilizzati per l’addestramento di vari modelli di IA generativa di cui si riportano i risultati.
L’addestramento dei modelli in locale (GPT-2 e T5) è stato effettuato su una GPU NVIDIA RTX 3060 Ti, mentre per modelli non locali è stata utilizzata la piattaforma OpenAI.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Scopri come Adamantia può rivoluzionare il tuo business
Clicca sul bottone per contattarci e ricevere una demo